High grade geospatial processing (feat. R-Tree's ) 🌲⚡️
From Browser fast to Blazing fast: DuckDB Rips 🦆💨
Introduction 👋
So last year, I created a web app called kreuzungen.world that calculates the number of waterways crossed by a gpx route. It was a fun little project to build and led to some interesting encounters.
The app was built using javascript in a way that required no backend.. Thats right, all the data fetching and processing was done in the browser. (No server costs 💸).
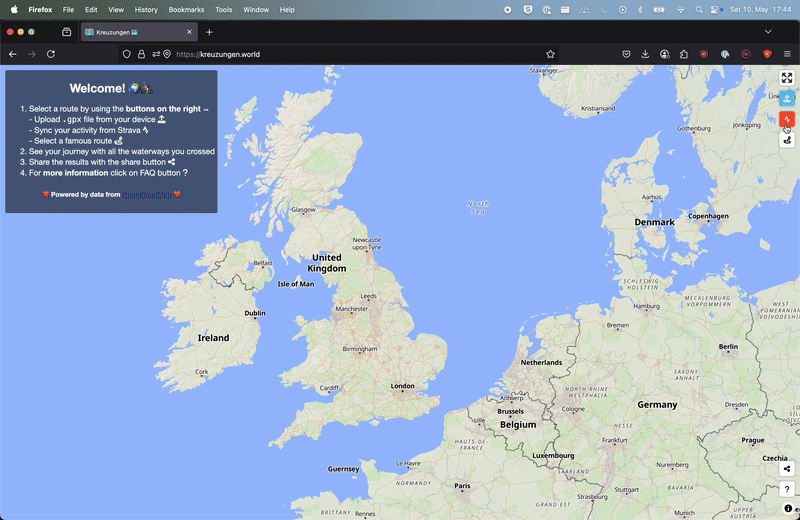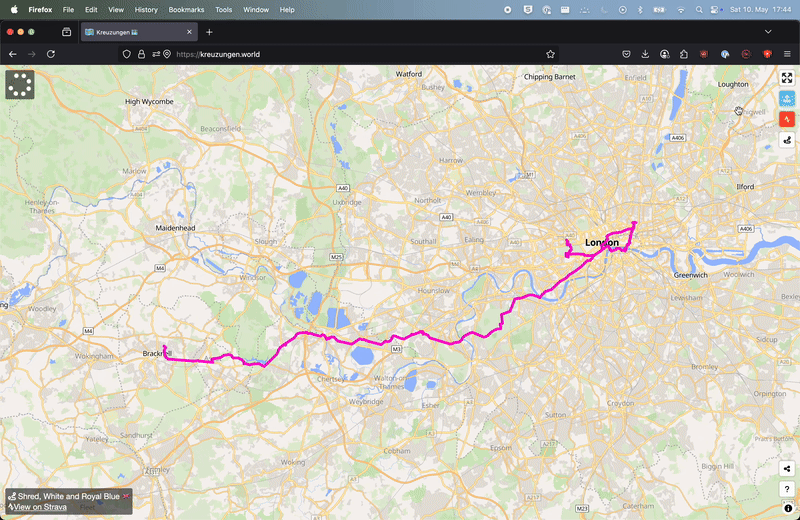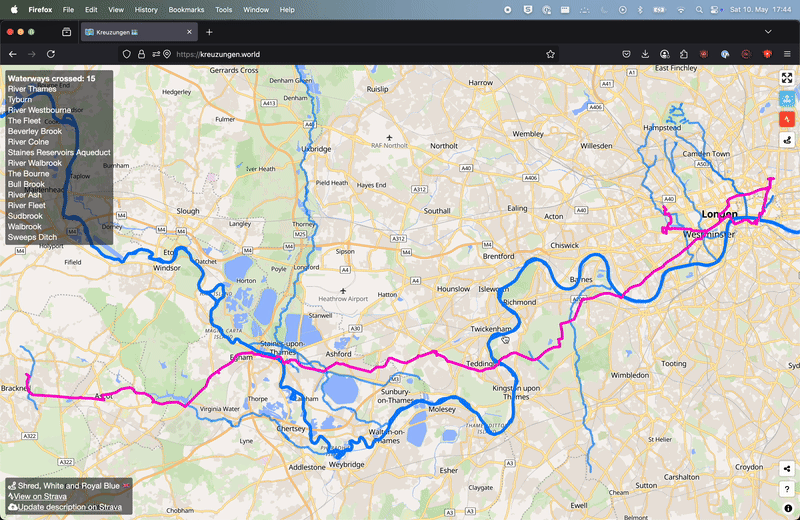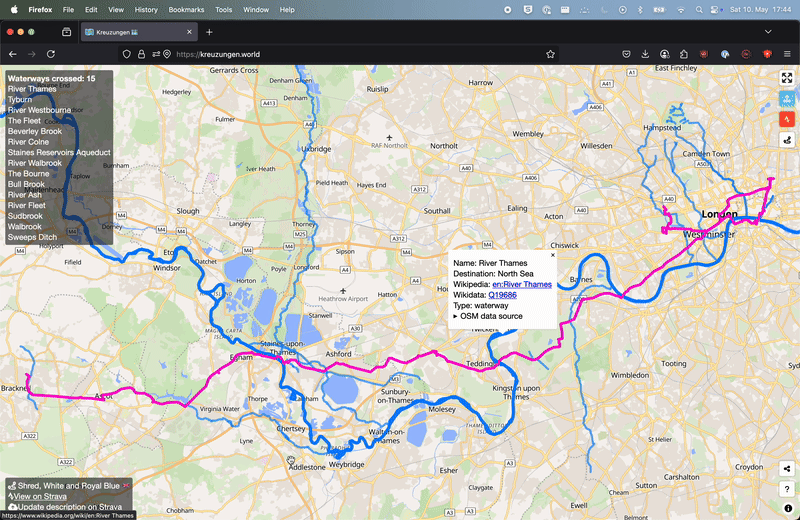
It uses the Overpass API to fetch the waterways data from OpenStreetMap and then uses turf.js to calculate the intersections between the route and the waterways. Pretty simple, right?
What’s been surprisingly rewarding is seeing people actually use it! From Japan to Argentina to New Zealand to the USA (where one kayaker uses it to track river crossings). It’s humbling to see something I made for fun, being used by people across the globe.
kreuzungen.world isn’t changing the world, but it is a great example of how open source software and open data can be used to create something (crossing rivers is not going to save lives, but my shred-buddies find it interesting, so that’s something).
The powerful client 💪
I want to point out my genuine surprise at how fast the browser does the geospatial processing… It just works, even on old devices, the performance is good enough. We are talking a couple of seconds for most routes. Including fetching the waterway data via OSM, render the calculated intersecting waterways on a vector map. Waterway fans are happy, I am happy too 😁
But, I am not completely satisfied… Recently I have had a craving for speed in my life, don’t know why, but I feel it. And fittingly I decided to revisit this problem and see how fast I could push this thing 🚴
I had an Idea 💡
River data doesn’t change that often, so by pre-processing the data and using a storage format optimized for querying it should be much faster My train of thought was something like this 🤔
- Pre-download waterways instead of waiting for the Overpass API 💾
- Use duckdb alone for fast geospatial queries 🌍🦆
- Implement R-Tree indexing to minimize intersection search space 🎯
- Apply two-step filtering: bounding box, then precise intersection 🔍
- Lightweight API Layer with endpoint for GPX upload 💻
Well folks, buckle up, because I took that idea and ran with it and it turned out to be a sprint! 🏃
The Setup 🛠
The entire solution is available on GitHub. Feel free to adapt it for your own needs.
The solution has two parts:
- Preparing the database
- Wrapping it in an API
Actually thats a lie, there is another part…
- The benchmarking! ⏳
I also included a benchmark with some different gpx files, because, well timing things makes sense (when you’re obsessed with speed 🎽).
The entire solution is built using open source tools and libraries and is available on GitHub. Feel free to explore and adapt it for your own projects! If you have any suggestions or feedback, please reach out. I’m always eager to learn and improve.
The project structure looks like this:
| |
The “Big Data” Preprocessing Pipeline 🚰
Let me walk you through the pipeline, which is at the heart of the solution, that transforms raw OpenStreetMap data into the DuckDB table optimized for spatial querying. This is the source of the Wasserwege API 🌊
Download OSM Data: Using extracts from Geofabrik rather than processing the entire planet file.
Filter Waterway Features: Using Osmosis, filter for waterway features from the OSM data. This dramatically reduces the data size.
Convert to GeoParquet: Using ohsome-planet. The format is columnar and much more efficient for analytical queries. This Java tool is amazing, it does a great job at converting the OSM data into a format that is easy to work with.
Build database for querying: I leverage dbt with the DuckDB adapter. This framework brings structure to data transformation workflows. It nicely separates the data transformation logic from the data engineering configuration. Makes a setup that’s easy to maintain and extend and minimizes boilerplate code.
R-Tree Indexing 🌳
The most critical optimization is the creation of an R-Tree spatial index to organize the geometries in a hierarchical tree structure.
When a query like “find all waterways that intersect with this route” is executed, the R-Tree allows the database to quickly eliminate vast portions of the dataset without checking each waterway individually. This reduces the time complexity from O(n) to something closer to O(log n).
An index can be created with a simple SQL statement, thanks to the duckdb SPATIAL extension:
| |
This single line of code provides dramatic performance improvements for spatial queries.
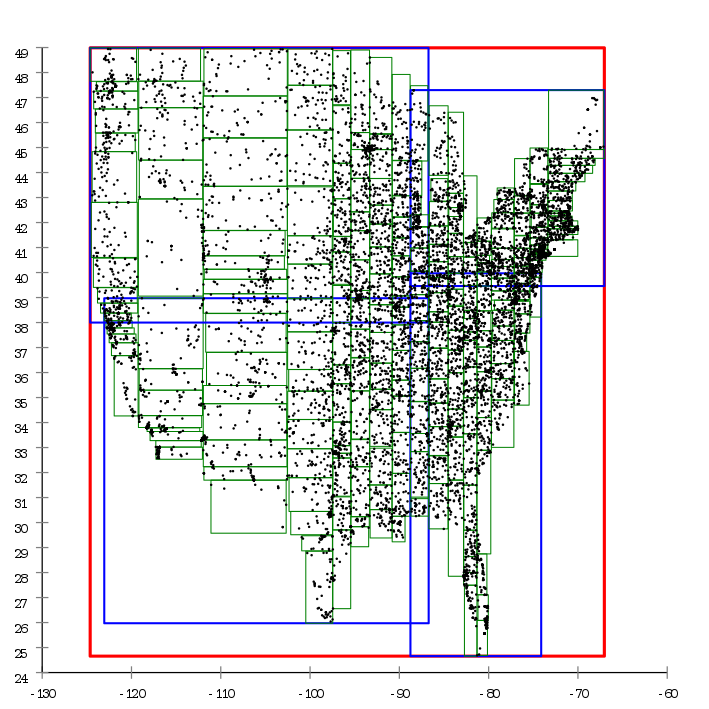
Imagine trying to find a group of friends at a festival… good luck if you have to search through the entire crowd. But if you know they will be at the beach stage, you can skip out the masses and search through only the people in the near vicinity. The R-Tree index is an ordering of data such that you quickly narrow down the search space to just the relevant geometries.
DBT-ing it all together 🧩
The waterways.sql model combines the transformations and creation of the R-Tree index.
| |
The output of this all is a local duckdb file pond.duckdb with a table waterways that contains all the waterways, configured ready for fast querying.
The API 🎮
The API is built using FastAPI, a modern web framework for building APIs with Python. My aim was to keep this lightweight and hand off the heavy lifting to the database. I added two endpoints to the API:
/healthcheck: A simple endpoint to check if the API is running and healthy and reports the number of waterways in the database./process_gpx: This endpoint accepts a GPX file, parses it, and finds the waterways that intersect with the route. It returns the results in a JSON format.
gpxpy library, which is a simple and efficient library for parsing GPX files. The GPX file is converted to a LineString geometry using the gpx_to_linestring function, which extracts the coordinates from the GPX file and creates a LineString object, this is then passed to the find_waterway_crossings function. | |
The Query ✍️
The core query that powers the intersection detection is remarkably simple (thanks to the R-Tree index and DuckDB’s spatial functions):
| |
This query uses the created index to quickly identify potential intersections, then it performs the exact spatial operation only on those candidates.
Quantifying the Gains 📈
To measure the performance gains, I created a benchmarking script (benchmark.py) that tests different GPX files against the API. The results showed a drastic improvement:
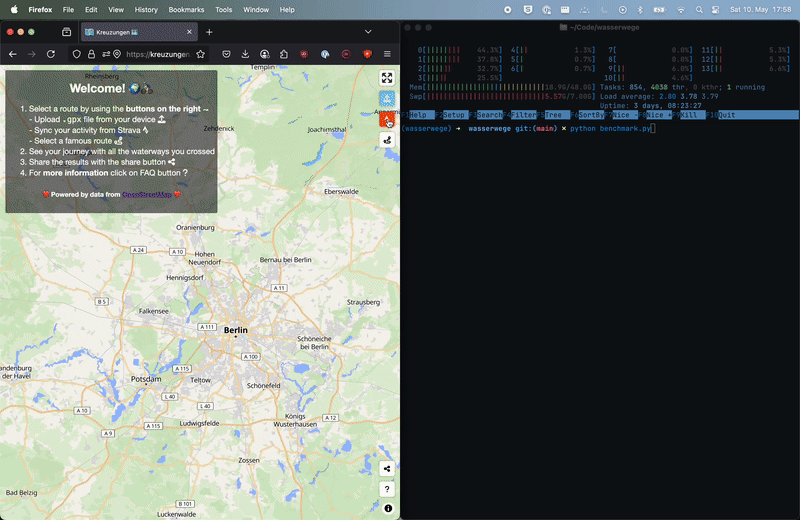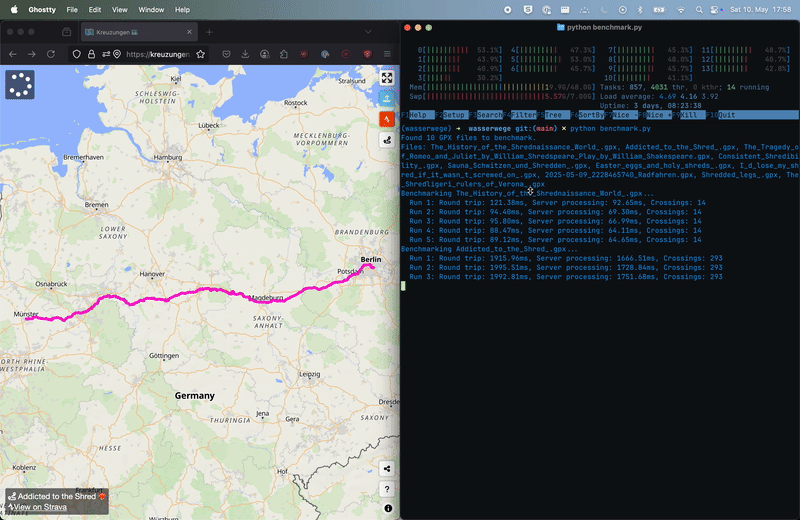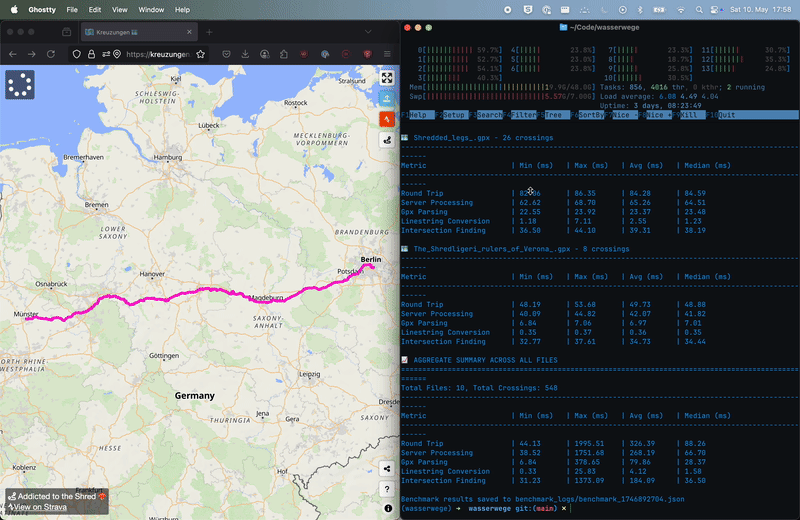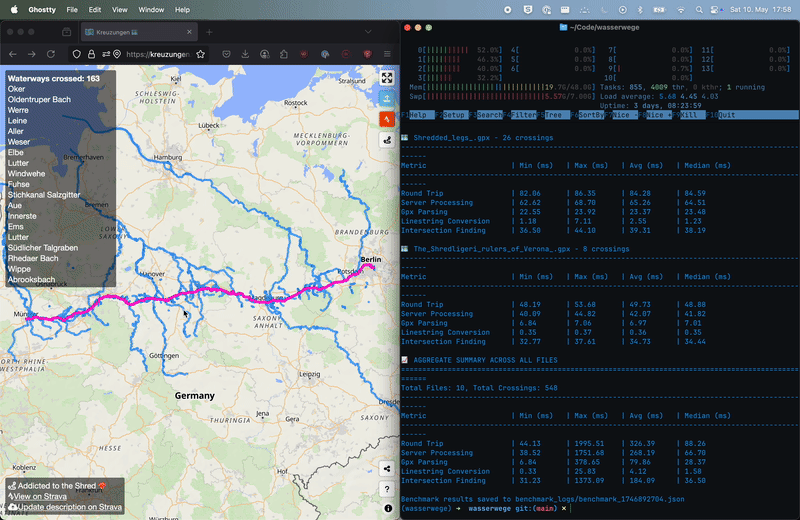
You can see the performance of the API in action. The benchmark script runs 10 different GPX files, each with varying lengths and complexities, and measures the time taken to process each file, and it runs before the old browser-based solution even finishes a single route.
This represents a biggggg in processing speed compared to the browser-based solution!
Conclusion: Performance is a Journey, Not a Destination 🧘
This experiment shows that with different tools and techniques, we can dramatically improve the performance of applications. What was already “pretty fast” in the browser is now much faster because of a change in architecture 🦆
I’ll be honest, I don’t even have a feeling of what a “fast” optimized response to this problem should be 😲
There are so many ways this problem can be solved using a computer, and each approach has its own characteristics.
I didn’t explore other optimizations, like using a different database or alternative indexing strategies. I could have written low-level code in Rust, but that would take far more time than I had available for this project.
We are lucky to have such fast tools available to us today to use for free, and can build on top of really well made software. This saves time ❤️
Seriously, a lot of the reason why someone like me can solve these problems is thanks to gluing together libraries and tools that are openly available on GitHub.
There are many layers of abstraction in this solution, a lot of code I’m not even aware of. Every tool I use is built on top of other tools, which are built on top of others, and so on. Many developers have spent countless hours pondering optimizations at each level, and it’s thanks to this combined effort that a single developer like me can build something this efficient. A solution that’s more than fast enough for my needs 🙇
Standing on the shoulders of giants isn’t just a saying, it’s literally how modern software development works. The R-Tree implementation I’m using might have taken years to perfect by dedicated algorithm specialists inspired by centuries of mathematicians thinking about geometry, and here I am, the tech-bro activating it with a single line of SQL in a database named after a duck! This ability to reuse the mental work of others, whether you are aware of it or not, makes this field so incredible. ✨
Takeaways: Performance is a Journey, Not a Destination 🧘
It’s deeply satisfying to see abstract ideas transform into real performance gains. What started as a theoretical hunch about spatial indexing and data processing became a real and measurable improvement. It’s a humble reminder that studying these concepts can actually lead to practical benefits when applied to the right problem.
Not everything in life needs to be fast, but in situations where it matters, a well-chosen index and thoughtful data pipeline might just be the solution you need! 🏁
Standing on the Shoulders of (Open) Giants 🙇
None of this would be possible without the incredible open-source tools and libraries that are available today.
OpenStreetMap Contributors: Every river and stream was manually mapped by volunteers in one of humanity’s most impressive collaborative projects 💚
Geofabrik: Provides free daily OSM extracts, saving countless hours of redundant processing. Thank you! 🙇
Osmosis: When OSM data is like IKEA (an overwhelming maze with too many options when all you need is cup), this tool helps filter just what you need 🕵️♀️
ohsome-planet: Transforms OSM’s simply-elegant-but-awkward data model (just nodes with tags and pointers) into the GOAT GeoParquet format 📦
DuckDB: Turns your laptop into a high-performance geospatial data warehouse 🦆
dbt, gpxpy, FastAPI: The building blocks that tied everything together into a coherent system 🧰